One paper, two journals, seven years, and what the publication system costs the people inside it.
In January 2025, I opened an email from the associate editor of the Journal of Experimental Psychology: Learning, Memory, and Cognition. The key sentence: “I no longer see a path for publication, and so am rejecting the paper.”
Three years of review. Three rounds of revision. A new experiment conducted specifically because the editor demanded it. And now, nothing.

This paper found a home at Cognition in 2026 1. But the full journey — from first experiment to accepted manuscript — took seven years. Three to design the study, collect data, build a computational model, and write the manuscript. Four more to get it published. Our experience was not uniquely terrible. That is precisely the problem.
The Study
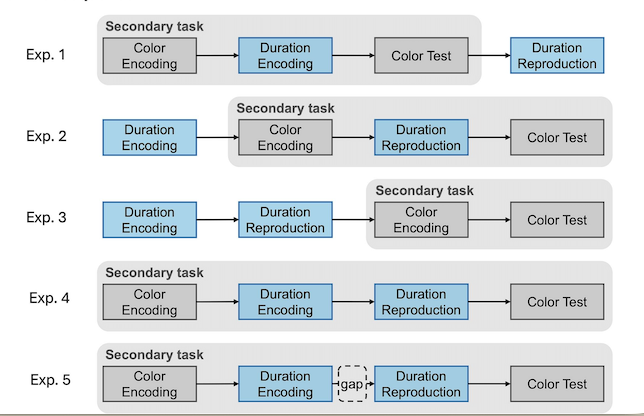
My former PhD students, Xuelian Zang (Linda), Xiuna Zhu (Fiona), and I designed a dual-task experiment: participants reproduced auditory durations while holding colors in visual working memory. The key manipulation was when the memory task overlapped with the timing task — during encoding, during reproduction, during both, or not at all. Four experiments, each isolating a different processing stage. A hierarchical Bayesian model that captured how memory load distorts time perception differently at each stage.
Three years of work went into this: designing the paradigm, piloting, running participants, fitting models, writing. Fiona’s PhD revolved around the project. We submitted to JEP:LMC in March 2022, confident the work was solid.
The First Blow
Four reviewers. Three were positive — one called it “an excellent paper,” another praised the “well-motivated, elegant experiment,” a third recommended publication after minor revisions. But the editor focused on the cumulative weight of concerns, many of which didn’t overlap across reviewers. Each saw something different to worry about.
The deepest concern was a design confound we hadn’t anticipated. By varying when the memory task overlapped with the timing task, we inevitably changed other things: how long participants held information in memory, the temporal structure of each trial, even whether memory load was blocked or mixed. The editor argued — reasonably — that readers couldn’t be sure our effects came from the manipulation itself rather than from these secondary differences.
Other concerns: our predictions about variability weren’t supported by the data. Our model hadn’t been tested against alternatives. Our analyses mixed model-dependent and model-independent measures. All fair points.
The Grind
We revised for months. Added a control experiment to test whether holding duration alone explained the results. Separated the empirical contribution from the modeling.
The reviewers were satisfied.
The editor was not.
The control experiment, meant to dismiss the confound, had confirmed that holding duration does influence reproduction. We interpreted this as consistent with our model. The editor read it as proof that the confound was real. We had also removed the CV analysis because it didn’t support our predictions. The editor found this unacceptable — hiding inconvenient results rather than confronting them. The reviewers who had accepted the removal were overruled.
The editor’s demands escalated: report every experiment separately. Run a new, ideally pre-registered, within-subjects replication. Control holding duration across conditions. Reinstate the CV analysis. Use larger sample sizes.
In effect, a request to redo the entire study.
The Long Silence
We wrote a candid letter. Linda had returned to China. Fiona, the main co-author, had graduated and was on maternity leave, and eventually left academia. We asked whether we could revise without new experiments.
Nearly two years passed before we could submit the revision.
The Replication That Backfired
We did eventually run the new experiment — a within-subjects design with all spanning conditions, exactly as requested. This time, data collected from China, from Linda’s lab.The core pattern held: memory load increased central tendency during encoding. But one interaction between load and spanning condition was not significant. Participants also appeared to shift strategies across conditions, muddying the waters further.
The editor’s verdict: the replication “did not support the case.”
Three years, three rounds, one new experiment — rejected.
The sting was specific. We had been asked to put our findings on the line, and we did. The replication largely confirmed our claims and one fell short, as replications of complex multi-experiment designs often do. But in the editor’s reading, partial replication was worse than no replication at all. The data we were told to collect became the evidence used against us.
A Fresh Start
We submitted to Cognition in 2025. New editor, new reviewers, new eyes. The reviews were tough but different — shaped by a working memory perspective we hadn’t fully inhabited. And here we stumbled into a lesson that could have saved us years.
The term “memory load” — central to our framing — meant something specific in the timing literature: the number of items held during a concurrent task. In the working memory community, “load” is a broader concept encompassing encoding difficulty, inter-item similarity, maintenance demands, and more. One reviewer showed that our color memory task didn’t just vary load — it varied general difficulty in ways that scaled non-linearly with set size. Similar colors could be grouped or confused. Probe difficulty increased as color space filled up.
It reshaped how we understood our own results. The revision replaced “memory load” with “set size” throughout — a small change in words, a large change in precision. New analyses showed that the effects held even when controlling for color similarity, which actually strengthened the argument: the number of items, not task difficulty, drove the interference.
The Cognition editor saw a path where the previous one had not. Two rounds of review, both constructive. Accepted in 2026. The paper is better for the journey. But “better” came at a cost measured in years and careers.
What I’d Do Differently
If I could go back to 2022, here is what I’d tell myself.
Speak the reader’s language, not your own. Before submitting, read ten recent papers from the target journal. Match their terminology. The vocabulary gap between timing research and working memory research cost us at least two years. We were saying the right things in the wrong dialect. “Memory load” and “set size” describe the same manipulation, but they signal membership in different scientific communities — and reviewers notice.
Don’t hide inconvenient results. When the CV analysis didn’t support our predictions, we removed it. Every subsequent reviewer asked where it went. Report it, discuss it honestly, explain what it means for the theory. Transparency is faster than evasion, and far more credible.
Separate your data from your model. The editor told us this in Round 1. We half-listened. Present empirical results cleanly, using model-independent measures. Then show what the model adds. When model-dependent and model-independent measures tangle, reviewers lose trust in both.
Know when to leave a journal. After the first revision at JEP:LMC, the editor’s tone was already skeptical. The door was “slightly ajar” — his words. We spent two more years pushing against it. A fresh submission to Cognition in 2023 might have yielded acceptance by 2024. Persistence at one venue is not always perseverance. Sometimes it’s sunk-cost thinking.
Design for the critique you know is coming. If your study compares across experiments, reviewers will find confounds — because changing one thing between experiments inevitably changes others. Include the within-subjects version from the start. We learned this when the replication we were forced to run produced messier results than the original between-subjects design.
What Should Change
These lessons are for researchers — people inside the system who can adapt. But some problems aren’t solvable by individual adaptation. They’re structural.
The PhD timeline doesn’t fit the publication timeline. Fiona designed this study during her PhD. She ran the experiments, built the model, wrote the manuscript. By the time it was published, her PhD was years behind her, and the paper that represented her deepest work didn’t exist on her CV when it mattered — during job applications, grant proposals, career decisions. A PhD lasts three to four years. Our publication process alone consumed four. The system rewards quick, safe, single-experiment papers over ambitious, multi-experiment, computationally rich ones. We tell students to be bold, then punish them with timelines they cannot survive.
Escalating demands should come with shared costs. The editor’s request for a new pre-registered replication was scientifically reasonable in isolation. But who bears the cost? Not the editor, who writes a paragraph. Not the reviewers, who read the result. The authors — one on maternity leave, one no longer in the field — must recruit participants, run sessions, analyze data, rewrite. When demands escalate across revision rounds, editors should ask: Is this proportional? Can these authors realistically deliver? And will the result, whatever it is, actually resolve my concern — or will I find new reasons for doubt?
Messy replications are still science. We replicated our own findings at the editor’s request. The core effect held; the interaction fell short of significance. Partial replication of a complex design with small-to-medium effects is exactly what statistical power predicts. Yet it became grounds for rejection — after being demanded as a condition for acceptance. This creates a trap: if the replication works, the paper survives; if it doesn’t, the paper dies and you’ve lost two years. For a PhD student building a career, the expected outcome of that gamble is not a publication. It’s a lesson in what ambition costs.
Coda
Cognition accepted the paper in 2026. The reviews were tough but fair, the editor constructive. The terminology lesson — “set size,” not “load” — genuinely sharpened the science. The paper is stronger for the journey.
Seven years of a research team’s life went into one paper. The question isn’t whether it deserved to be published — three positive reviewers recognized its value at the very first round. The question is whether the system can afford to take seven years to agree with them.
The next time I design a study this ambitious, I’ll plan the publication strategy as carefully as the experiments. Because the science was never the hard part.
- Zang, X., Wu, J., Zhu, X., Allenmark, F., Müller, H. J., Glasauer, S., & Shi, Z. (2026). Duration reproduction under memory pressure: Modeling the roles of visual memory set size in duration encoding and reproduction. Cognition, 271(106479), 106479. https://doi.org/10.1016/j.cognition.2026.106479
Note: I proudly used Claud AI to sharpen the writing, but all ideas and experiences are my own.